Best Practices
Creating and Editing Workflows
Here is a starting point to develop your own style of workflow development. There is no single best way to develop Flux workflows, but we have had success with this approach,
- Download an example and upload it into your repository, or select an existing workflow in your repository
- Edit the workflow’s name and save it as /CURRENTWORKFLOWNAME-1 (Note the “-1” suffix)
- Get the workflow running with some basic happy-path functionality
- Now rename and save – /CURRENTWORKFLOWNAME-2 (Note the “-2” suffix)
- Extend it
- Run it - test it - Correct it.
- When running successfully, save it to the repository
- Now rename and save -3
- Tweak some more. Add in more functionality, exception processing, etc… Keep incrementing the version so you can go back a version or two if required.
- If you are writing database statements or long Process Action command lines, open an editor (Notepad or Notepad++ for example) and keep all scripts and SQL statements in a file. Then copy and paste into the Flux dialogs.
- Now define a strategy for your namespaces (e.g., by department, customer, type of process, etc.) and create a corresponding runtime config – for the root namespace and any namespaces required for testing.
- Test the root namespace settings, then extend the namespace deeper to match your namespace strategy
- Build your QA and production default error handler and test
- Perform your integrated testing
- Finalize documentation
- Cleanup and delete the older versions of the workflow.
Synch Flux Engines to a Network Time Server
Do not assume that multiple servers in a Flux cluster will have synchronized system clocks. There are many reasons why system clocks can deviate and the only safe means to assure synchronization is to have all the servers update their times from a network time server.
Error Handlers
When an error occurs in a workflow that triggers an error handler, the error handler’s actions are inserted into the workflow while the error handler runs.
To help operators understand which actions belong to the error handler, and which actions belong to the main workflow, we recommend adding some descriptive text to the name of each action in the error handler to help it stand out — for example, prepending all of the error handler’s action names with “ERROR HANDLER”.
Using this technique when you design your error handlers will help operators immediately and visually identify which components are part of the workflow properly and which components have been inserted by the error handler to remediate an error.
Namespace Best Practice
Namespaces are the organization structure in Flux that allows you to name your workflows and group them together in logical units.
Namespaces are used in several places through Flux:
- The Runtime Configuration and Runtime Variables.
- Operations performed using the Java API and the Command Line Interface.
- Security permissions.
Because of the wide range of applications for namespaces, we’ve developed a few simple best practices to keep in mind when building your namespace structures.
Workflows should share a common namespace folder in any of the following scenarios:
- Multiple workflows will access the same set of underlying data (FTP server locations, web service applications, etc.). Sharing a namespace will allow these workflows to use the runtime configuration to access the same set of underlying data, which will only need to be updated in a single location.
- Multiple workflows will share the same security restrictions, or your users will only need to access/operate on a particular class of workflow. Namespaces can help distinguish workflows by type, allowing your users to see only the workflows that interest them.
- Users will often need to perform batch operations on a set of workflows. Namespaces allow you to perform operations at the namespace folder level, so users can quickly perform tasks like pausing, expediting, or removing entire groups of workflows in a single operation.
File Transfer Workflows and Error Handling
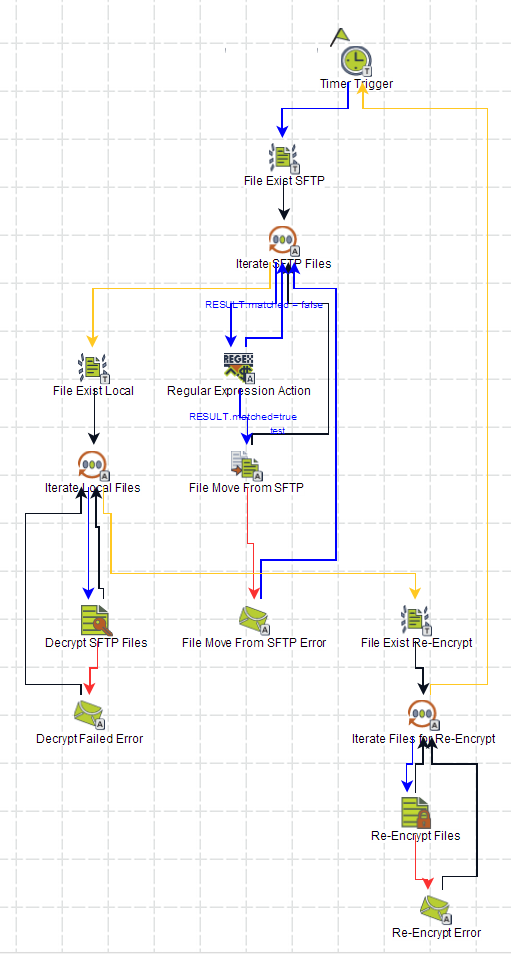
A common pattern encountered by workflow designers involves a workflow that fires at a given time every weekday, then polls a remote server for files that are fetched and processed. Often such workflows need to support selecting files for processing based on a naming convention – such as a file description followed by a valid date in the filename.
A best practice in Flux workflow design is accommodating for exceptional situations during processing. Often customers utilize wild card processing to select and process sets of files, not realizing that if a file in the set fails to correctly process, all following files in the set will fail to process.
The above workflow starts with a timer trigger to fire at specified intervals. A File Exists Trigger fires collecting the set of filenames available to fetch from the remote server. Then, using a For Each Collection Element Action that submits each filename to a Regular Expression Action to compare a substring of the file to match a valid date (in yyyy-MM-dd format). If a filename matches the regular expression, the filename is submitted to a File Move Action where the file itself is moved to a local folder to be decrypted. If a filename does not match the regex expression, then the flow goes back to the For Each Collection Action to pick up the next filename in line.
After fetching the remote files, the workflow uses another file trigger to pick up the filenames of local files to be decrypted. This pattern of using a For Each Collection Element Action provides per-file processing, meaning (in this case) if the decryption action fails, the Flux Operations Console has access to the filename of the file that failed (rather than a list of files and no knowledge of which file failed to decrypt). This same pattern is used again to re-encrypt the files.
If anything should fail in the workflow, mail actions send an email to a set of specified email addresses to alert the customer’s team that something failed. After the email has been sent (containing the filenames which failed) the normal processing of the remaining files continues.
Directories, server names, and numerous other elements of this workflow can be externalized to runtime configuration files allowing the same workflow to be used as a template for many purposes, providing consistency of deployment.
Documenting a Flux Environment
The following information should be kept in an editable document, reviewed quarterly, and made available to Flux Support Personnel when requested for assistance in Flux-related issues. While this list is not exhaustive, it should serve as a starting point for keeping your Flux environment managed.
- Flux version in use - from the output of running java -jar flux.jar.
- A listing of the Flux key in use (from fluxkey-8.0.txt for example).
- A diagram of the configuration showing the interaction of the Flux engine with other engines, agents, firewalls, proxies, and remote processing nodes.
- Runtime Configuration Properties - which may be in a file or set via code.
- Engine Configuration Properties - which may be in a file or set via code.
- Agent Configuration Properties - which may be in a file or set via code.
- The classpath used to start the Flux engine.
- The JVM Vendor, release, and version of Java. Also whether the Java installed is a JRE or JDK and 32 bit or 64 bit.
- The parameters used to start Flux - either batch files or service property settings. In particular, min and max heap size and the location of Java HOME are required.
- The service account names and privileges allocated to the Flux processes
- A list and description of Custom Actions and Flux Java Listeners
- A list and description of 3rd party jar files used in your application and in the classpath to Flux.
- A database export of the Flux_Ready Table and Flux Cluster table when Flux is running on a peak processing day. Note that doing a CSV export often does not properly render large numeric values (such as primary keys) so a database export gives a more complete rendition.
- Machine type Flux is running on
- Virtual or Physical
- If Virtual - name and version of the virtualization software
- If Physical - name and model of the physical machine
- Memory of the virtual or physical machine
- Number of processors, and number of cores per processor
- Virtual or Physical
- Operating System installed and 32 bit or 64 bit.
- Database Vendor, Version, and JDBC Driver in use. A copy of the URL Connection String (excluding any sensitive information)
- Application server and version in use (Weblogic, Websphere, Tomcat, JBoss, none)?
- Change log of specific changes, and the purpose of these changes, made to the Flux environment.
Version Control of Workflows
Flux does not provide a built-in VCS mechanism. Workflows can be downloaded to XML files, from the Repository and the Designer, so if version control is required, Flux recommends the following:
- During workflow design, save workflows to the Repository as normal.
- Once the workflow is in a state where it should be committed to the VCS, use the “Download” option from the Repository to download a local copy of the file.
- If you need to test two different versions of the same workflow, or would like to have a way to tell the different stages of a workflow apart, append a suffix of your choice to the workflow name (e.g., -A, -1, etc.).
- Place the file into the VCS and commit / update as normal through the VCS tool’s interface.
- Once you have your final workflow design, feel free to clean up old versions of the workflow from the workflow repository.
Many VCS applications will offer XML comparison/change tracking tools out of the box, while others, like Git, can be extended through custom merge drivers, allowing you to track specific changes within a workflow using standard VCS tools.
Version Control of Flux Environment
In addition to Flux workflows, ensure the following files are under version control so that prior releases can be restored, and differences can be detected and reviewed.
- runtime config
- engine config
- agent config
- batch files using scripts shipped with Flux for the baseline
- custom actions and Java classes
- 3rd party jar files used in your application
Environment Control
Keep your Flux environment clean to make problem determination simpler and more straightforward.
- Keep only one version of the flux.jar and fluxkey-
.txt files in the classpath - Keep the exact same version of Java across environments
- Keep the exact same version of the flux.jar and flux.war files across environments
Deployment
Coordinating activities on a Flux deployment is essential to provide for effective rollout through different environments such as Dev to QA or QA to production.
- Make SURE the license key is zipped before transferring to the destination computer
- Have a detailed document of the custom environment (if not deployed in the Flux-version folder) including not only info about customized scripts but also noteworthy configs (network file system, etc)
- Be able to update files (flux.jar, etc.) and/or license keys in that environment following the document
- All Flux jars in a production rollout sequence should be the same. Can have different jars when testing new releases but production should never have a newer flux jar than dev or qa.
- Make sure that the user starting Flux/Flux services has all the appropriate permissions over the DB, the file system (writing logs, executing scripts, etc), the remote servers it needs to access to execute processes on agents, private keys, etc.
- Adhere to your namespace design guidelines - as mentioned previously in this document.
Maintenance
- Run a weekly job on flux database tables getting row counts. Review row count growth and shrinkage and ensure changes are reasonable and understood.
- Ensure all servers have the same time across the network (the network time server)
- Construct and maintain documentation on Java actions and the incorporation of third-party jars. In particular Jersey and Free marker
- Keep current on Java Virtual Machine updates
- Keep current on the JDBC driver jar for your database version
- Use log4j to allow changing to debug without server restart.
- Ensure that all runtime variables are still in use and that all passwords are encrypted
- Ensure runtime variables are separated from runtime configuration properties (in the same file, but using a comment line to keep ‘em separated. This makes it a whole lot easier when maintaining runtime config properties)
Troubleshooting
Permissions: Make sure the user running Flux (this is the logged-on user when running from the batch/shell scripts, or the service account when running as a Windows service) has Read/Write/Execute permissions over the Flux folder and any local and remote locations Flux needs access to.
If a workflow/action is failing to execute (i.e. a Process action that runs a command on a remote server that seems to be stuck in FIRING), please check the system logs and security audits. The permissions for running the command are a customer environment variable and will change according to each company’s setup.
Where to find the Flux logs
When using the default Flux installation:
The engine logs can be found in the root of your Flux installation folder (usually located in ‘C:\flux-8-1-x’).
- The logs are named ‘flux-
-dd-MMM-yyyy.log'.
The operations console logs are also located at the root of your Flux installation folder
- The logs are named ‘opsconsole-dd-MMM-yyyy.log’.
Where to find system log files
If you’re running Linux, UNIX, Solaris, etc. here’s a list of system log files and how to find them and view them:
http://www.cyberciti.biz/faq/linux-log-files-location-and-how-do-i-view-logs-files
If you’re running on Windows, you can refer to the page below to know where to find the system logs and view them using the Event Viewer:
https://support.microsoft.com/en-us/kb/308427
For further troubleshooting, head over to our Troubleshooting page.
Java Coding
Close any iterators: Make sure you close any flowchart element or repository iterators after using them. Leaving them open will slow performance and consume memory.
Performance Considerations
- Apply any recommended indexes on the Flux database tables. Setting indexes sometimes leads to a huge increase in performance. Also, make sure that your Flux tables are properly optimized. Most performance problems can be resolved by proper database table optimizations.
- Use the concurrency throttle settings and MAX_CONNECTIONS configuration property fine-tune the amount of load on your database. You can also throttle the number of flow charts running across the entire cluster in a particular branch of the flow chart tree.
- Use one set of Flux engines to add/remove/monitor flow charts and another set of engines to actually run the flow charts. The set of Flux engines that is used to add/remove/monitor flow charts should be stopped and should not run flow charts. The only purpose of these add/remove/monitor engines is to update and query the database, not to run flow charts. Use a Flux cluster to share the flow chart load.
- Set the FAILOVER_TIME_WINDOW configuration property to a higher value than the default of 3 minutes. For example, if you have a FAILOVER_TIME_WINDOW configuration property set to 15 minutes, you will see Flux update the heartbeat of all the flow charts in the database every 5 minutes. If you have a significant number of flow charts, you should tune this parameter such that Flux does not query your database too frequently.
- When increasing the FAILOVER_TIME_WINDOW, be aware that if a Flux engine crashes for some reason, it will take longer for another clustered Flux engine to failover and rerun the failed flow chart.
- Note: you should use the same FAILOVER_TIME_WINDOW configuration property on all Flux engines in the cluster.
- If your scheduled flow chart firing times are very close together, you might want to increase the SYSTEM_DELAY configuration property. For example, the default SYSTEM_DELAY is 3 minutes, meaning that Flux scans the database for flow charts to run every 3 minutes, unless notified earlier to do so. This scanning frequency might be too much if all your flow charts are scheduled to fire at exactly, or nearly exactly, the same time. You might want to increase your SYSTEM_DELAY to a value like +10m (every 10 minutes).
- Note: you should use the same value on all Flux engines in the cluster.
- To increase the responsiveness of engines in a Flux cluster, you should allow cluster networking (set CLUSTER_NETWORKING to true, which is the default value). This way, all Flux engines in a cluster immediately know when a new flow chart is added through one of the Flux engines.
- For example, if you are adding flow charts using a stopped engine, the stopped engine can notify the other engines in the cluster via networking that a new flow chart has been added. The running engines can immediately retrieve and start running that flow chart.
- Without cluster networking, the running engines must wait until the SYSTEM_DELAY polling interval has elapsed.
- Note: Cluster networking is not needed for correctness, but it does help increase the responsiveness of the engines in a cluster.
- If you are using a data source, make sure that the connection timeout is long enough. For example, if some of your flow charts take a long time to execute, you want to make sure that your connections do not time out during flow chart execution. Also, make sure that your data source connections are refreshed and tested periodically.
- Flow charts that are scheduled to fire at closely spaced frequencies will result in Flux putting a load on your CPUs and database at flow chart firing time. This load is due almost entirely to the running flow chart, not Flux itself.
- To minimize the load that Flux can put on your system, properly configure your Flux engines to limit the number of concurrent flow charts and database connections. These limits are applied using concurrency throttles and the MAX_CONNECTIONS configuration property.