Background
Flux orchestrates file transfers and batch processing. Without human intervention, Flux orchestrates the transfer of high volumes of data and business transactions across different platforms and systems. Flux then manages batch processes performed against this data, including conversion of data, data compression, encryption, enterprise-specific processes as well as secure transfer for backup, replication, and distribution of files.
IT organizations realize that not all enterprise processing is interactive and web driven. Enterprises need to process high volumes of data not suited for interactive processing. IT organizations must optimize hardware and network resources to balance these resources.
As enterprises expand the sharing of data across disparate platforms, operating systems, and database management systems, reliable file transfer and batch process orchestration becomes indispensable.
Flux excels in satisfying circumstances where:
- Files and data need to be transferred unattended to reduce processing time and expense, increase reliability, and meet service level agreements.
- File and data need to be transferred in a secure and reliable manner among different platforms and systems.
- High volumes of data need to be moved between many different functions running on a variety of platforms and machines.
- File transfer and related processing are time-driven, process-driven, or manually triggered.
- Processes need to be set up to run with the same programs and same (or varying) parameters, ensuring data integrity and consistency of processing.
Flux provides the solution core for many top-tier banks and financial service providers, including solutions for check image exchange, image and document delivery, treasury management, wealth management, and institutional investor solutions (to name just a few).
All of these solutions support high-volume, high availability, and highly-reliable processing that offers each institution opportunities to increase revenue and garner new customers, while reducing operational and administrative costs. Flux’s ease of integration into multi-platform solutions, its extensibility using open Java and Web Services APIs, and its unique clustered and easily-scaled architecture provides the underpinnings for current and next-generation product offerings.
Architecture
Before using Flux, you should become familiar with Flux’s architecture. The Flux engine is the core component of Flux that drives all scheduling and execution. A Flux engine can be run on platforms like Windows, UNIX, Solaris, IBM mainframes, or any other operating systems with appropriate Java support.
Every engine participates in a cluster, which is defined simply as one or more engines that engage in peer-to-peer execution of your workflows and tasks. Because every engine is, by default, participating in a cluster (even if the cluster only contains the one engine), this document may use the terms “engine” and “cluster” interchangeably.
Flux’s peer-to-peer architecture is oriented by a backend database. If a persistent database is not available, Flux allows you to run a standalone engine using the built-in Apache Derby database, which provides persistent storage to the file system. An optional in-memory H2 database is also available for fast, non-persistent, non-distributed execution.
End users can interact with the Flux cluster through a number of endpoints, including a user-driven Operations Console that allows users to define and execute workflows, and software endpoints for developers to tie into Flux (see “Flux Clients” below). The following diagram outlines the architecture and interactions between Flux, its users and clients, and the backend data storage layer.
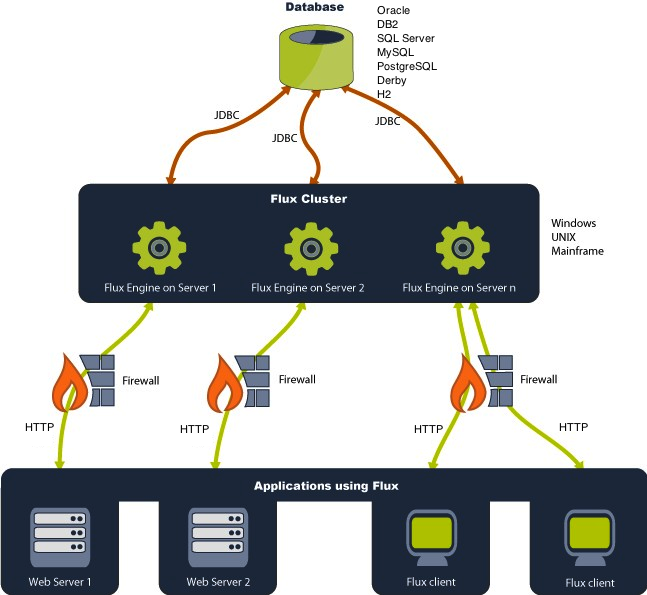
For a complete list of operating systems and platforms known to work with Flux, refer to Technical Specifications.
Flux Clients
Flux clients define how the Flux software executes tasks. These clients connect to Flux clusters. The protocol used for client-engine communication is HTTP.
A Flux client may be:
- A web browser (using the Flux Operations Console)
- The Command Line Interface (CLI)
- Application code using Flux APIs
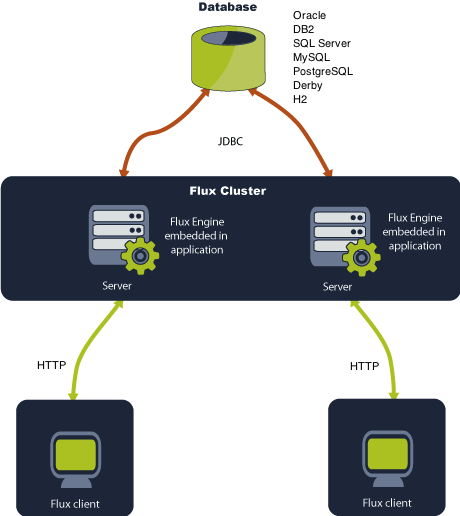
Flux with Java SE
The Java Standard Edition (Java SE) gives you a complete environment for doing applications development on desktops and servers. It also acts as the base for the Java Enterprise Edition (Java EE) and Java Web Services.
The diagram below illustrates Flux running on the Java SE platform.
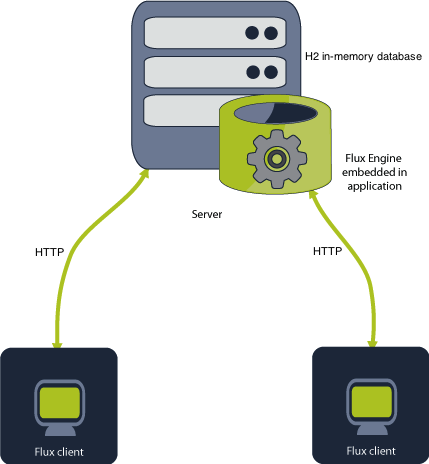
Flux with In-Memory Databases
You can use Flux with its embedded, in-memory database to create a fast and simple environment for Flux to run in.
The following diagram displays the architecture of Flux using the Java SE platform with its embedded database.
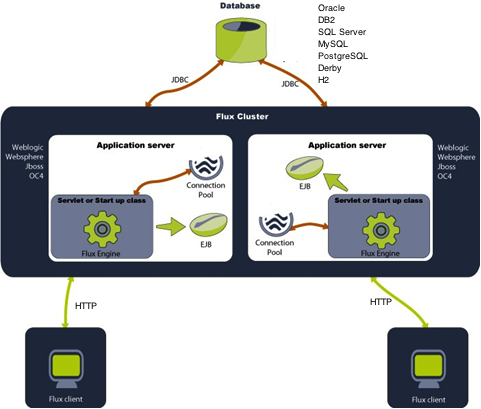
Flux with Java EE
The Java Enterprise Edition (Java EE) is the standard for developing multi-tier enterprise applications. The Java EE platform can simplify enterprise applications by basing them on standardized, modular components; by providing a set of services to those components; and by automatically handling details of application behavior; all without complex programming. If you are running Flux on a Java EE platform, it is suggested that you do not depend on the Java EE JAR files that are packaged with Flux, as these files could be out of date. Instead, we recommend you use the EJB and JMS JAR files that are distributed with your application server.
The following diagram illustrates Flux running on the Java EE platform.
The Cycles and States of the Flux Engine
Like most software applications, Flux has a simple basic lifecycle: it is created, initialized, and later disposed. During initializing, Flux uses a provided configuration to connect to your database and, optionally, application server. Once initialization is finished, clients can interact with Flux, although workflows will not execute at this stage of the lifecycle. From here, engines can start, which will allow workflows to begin executing – running engines can then be stopped, which will stop workflows from firing (clients can still interact with Flux after the engine is started and while the engine is stopped). Finally, Flux can be disposed of – this stops Flux from executing workflows and accepting user submissions. From here, the engine must be created again before it can be used.

More simply, this means that Flux can be in one of three states: Stopped, Running, and Disposed. When Flux is first created and initialized, it enters the Stopped state. From here, Flux can be started, proceeding to the Running state. Flux can move between the Stopped and Running states indefinitely (you may occasionally need to stop Flux to prevent workflows from running, but still allow users to continue working with the software).
When you are ready to shut down, you can transition Flux to the Disposed state. From here, Flux will not run or accept connections and must be restarted to continue working.
This lifecycle is demonstrated in the following diagram:
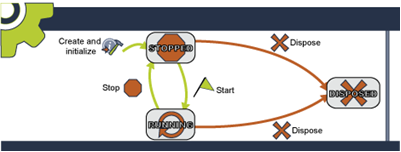
The Cycles and States of Flux Workflows
When working with Flux, all tasks and schedules are defined as workflows. A workflow is a series of triggers, which define when your tasks execute, actions, which define the tasks to run, and flows, which define how triggers and actions interact with one another and define the logical order that your tasks progress.
All workflows begin with a start action. The start action can be any trigger or action in Flux, and marks the first item that will execute. In the case of a trigger, this means that the start action defines the first condition that will kick off the workflow, and with an action, it defines a task that will run immediately when the workflow begins executing. You can even define multiple start actions to specify concurrent tasks that launch a flow, or concurrent conditions that must be satisfied before a flow can begin.
A common workflow might include a File Exist Trigger as its start action. This trigger waits for some number of files to arrive at a specified remote or local endpoint, then fires, allowing the flow to progress and passing along some useful. From here, Flux will follow an outgoing flow to determine the next step to run – often, from here, a File Copy Action that transmits the files from their original location to a new endpoint.
In this way, the workflow can continue from triggers and actions, using flows, in a logical progression that allows you to define how your tasks proceed. These triggers and actions might include timer triggers that wait for a particular date, time, or delay, email triggers that wait for incoming emails to arrive, or auditing triggers that wait for an event to occur in Flux or an external software system. You can even create your own triggers and actions to plug into Flux — this makes it easy to create new workflows that tightly interact with your application.
As Flux progresses through your workflow, the workflow will transition through several states. There are two types of states: superstates and substates. Each workflow will always have one superstate and one substate.
Superstates
A workflow can have one of two superstates: Normal or Error. If a workflow is in the Normal superstate, it is executing as expected by the workflow design. If a workflow is in the Error superstate, it means an error has occurred that the workflow design has not explicitly accounted for, and the workflow has entered an error handler to attempt to remediate the error or alert a user that the error has occurred. If a workflow in the Error superstate is also in the Failed substate, Flux will not attempt to automatically recover from the error and must be manually recovered by an end-user.
Substate
A workflow can have one of several substates. Aside from Failed, which always corresponds with the Error superstate, these substates can appear while a workflow is in either of the possible superstates.
- Waiting: The workflow is not immediately eligible for execution and is waiting a particular time or internal condition. A waiting workflow might be waiting at a timer trigger, waiting for a concurrency throttle position to become available, or for a file trigger, waiting for the next scheduled polling.
- Firing: The workflow is executing an action.
- Triggering: The workflow is waiting for an event and will execute as soon as the event occurs. For example, an audit trail trigger or manual trigger will run as soon as the triggering event appears. This differs from the waiting substate because a waiting workflow may not necessarily execute immediately on the next poll (for example, a file exist trigger might poll but find no file and so reschedule for the next polling), whereas a triggering workflow can be expected to immediately fire upon the event (assuming that no condition occurs which would delay this, such as a concurrency throttle filling up before the event arrives).
- Paused: The workflow has been paused by a client. Flux will never automatically pause a workflow and must be instructed by a client. Once paused, a workflow must be manually resumed to continue executing.
- Joining: The workflow is waiting for multiple incoming flows before proceeding from a certain point. A workflow will be in this substate when multiple concurrent flows arrive at a single point which is configured at a join point. The flow will resume when its join condition is fulfilled.
- Failed: The workflow has encountered an error and cannot automatically proceed. This substate can only occur in the error superstate. If a workflow is in the failed state, the workflow has entered an error handler and encountered an error action that stopped the flow. From this substate, the workflow can be recovered (resuming the workflow from its last successful state) or removed by a client.
- Finished: The workflow has completed executing. This means that the workflow has reached a point where there are no outgoing flows to follow. The engine will automatically remove the workflow after some time, but it may remain in the finished state while the engine performs cleanup.